
ポインタとはC言語のプログラムでよく使われるもので、Go言語でも使われる。しかしながらポインタは初見で見ると理解に苦しむ概念の1つだと思う。簡単に言えば、ポインタとは”アドレス(メモリー内の場所を特定する)を特定する情報”のことで、図にするとわかりやすい。
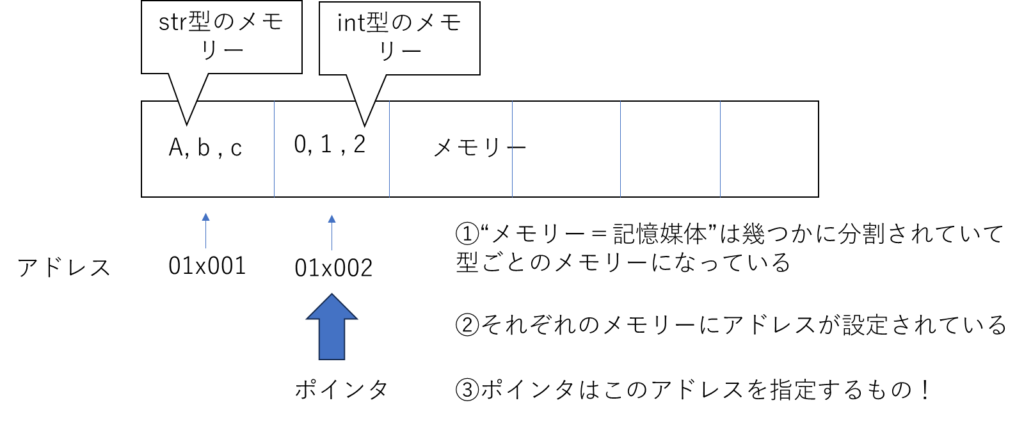
こんな感じ。感覚的に分かり易いと思う。メモリーごとに型があるからこそ、明示的であれ暗示的であれ型を指定する必要がある。そうじゃなきゃプログラムはその情報をメモリーのどこに記憶して良いのわからないし、取り出すこともできない。
var n = 0このシンプルな変数の宣言を考えてみる。この変数を宣言すると、プログラムはn=0をアドレス”01×002″にあるint型専用のメモリーに保存する。ユーザーは普段そんなの気にしないけれど、背景にあるプログラムはそうやって動く。実のところGoでもjavaでもC#でも、どんなプログラミング言語でもそうやって動いているから、ユーザーがポインタを指定しないプログラミング言語でもポインタの仕組は背景で必ず動いている。意識しないだけでね。
じゃあなんでそんな面倒なポインタなんて使うの?
ポインタは変数の宣言ほど直感的に理解しやすいものじゃないし、なんならポインタを指定しないプログラミング言語すらある。なのになんでポインタなんて使うの?と言われれば、当然その方が便利な場面がけっこうあるからである。
- ポインタを使えば戻り値を沢山増やせる
関数では引数は無限に設定できるが、戻り値は1つしか設定できない。でも、幾つかの出力結果が欲しい場面というのは結構ある。そんなとき、引数にポインタを指定すれば、その型を持つアドレスから複数の出力結果を引き出すことができる。これはさっきの図に立ち戻れば理解しやすい。ポインタでない引数では、分割されたメモリー内の0とか1とかaとか、そういう限られた変数しか指定できない。ポインタではアドレスごと指定するから、そのアドレスに含まれる変数すべてを対象にできる。 - ポインタを使えばメモリ効率を上げることができる
ポインタを使うことでデータのコピーを避けることができる。配列や構造体をそのまま関数に引数で渡そうとするとコピーが発生する。もし要素数10000の配列を渡したら、10000要素分そっくり全て別のメモリにコピーする。メモリが余計に使われ時間もかかる。そこで、配列や構造体そのものではなく、ポインタを渡すことによって、無駄なコピーを避けることができる。大きなデータ構造をコピーする代わりに、ポインタを介してデータにアクセスできるため、メモリ使用量が減る。
https://sync-g.co.jp/sjobs/c-pointa-beginner/ - ポインタを使えば動的にメモリを割り当てることができる
配列は一度宣言してしまうと後から大きさを変更できない。メモリの割当関数では、C言語ではmalloc()を使うが、Goではnew()やmake()を使う。これにより、メモリを確保して配列の大きさを自由に変更できる。new()関数は、指定した型のゼロ値で初期化されたポインタを返すもの。新しい変数へのポインタを取得する際に使用される。make()関数は、スライス、マップ、チャネルなどの組み込みの参照型データ構造のメモリを割り当てる。make()関数は、メモリの割り当てと初期化を同時に行う。 - ポインタを使えば大きなデータを関数に渡す際に効率的に処理できる
関数に引数を渡す方法は、値渡しと参照渡しの2つがある。値渡しでは、関数内での変数の変更が呼び出し元に反映されないが、ポインタを使った参照渡しでは変更が反映される。これにより、大きなデータを関数に渡す際に効率的に処理できる。 - ポインタを使えばデータの挿入や削除が容易になる
ポインタを使用することで、リンクリストなどの動的なデータ構造を作成できる。これにより柔軟性のあるデータ構造を実現し、データの挿入、削除などが容易になる。 - クラッシュやエラーの防止
ポインタを正しく扱うことで、メモリのセグメンテーション違反や無効なメモリアクセスなどのエラーを回避できる。
補足:リンクリストってなに?
リンクリスト(Linked List)は、データの集まりを表現するためのデータ構造の一つ。データ要素は、ノードと呼ばれる小さなオブジェクトに格納され、それぞれのノードは次のノードへの参照(ポインタ)を持っている。このようにして、データ要素がリンクによって連結されることから「リンクリスト」と呼ばれる。リンクリストは動的に要素を追加・削除でき、メモリの使用効率が高く、挿入と削除が高速にできる。リンクリストは、特に要素の追加や削除が頻繁に行われる場合に有用なデータ構造である。
リンクリストと配列は概念的に似ていて、大きな枠組みに複数の要素が格納されている点では同じである。しかしこれらは違うものである。リンクリストと配列の違いは、メモリ領域を跨ぐか否かという点にある。たとえばint型の配列であれば、int型のメモリー領域のみに保存される。一方で、リンクリストでは要素(ノード)がそれぞれ次の要素へのポインタを持つので、メモリー領域を跨いで保存できる。これにより動的なサイズ変更や要素の挿入を頻繁に扱う場面で、リンクリストの利点が発揮される。
前提知識
記憶媒体であるメモリーには、メモリー内の場所を特定するための指標がある。それがアドレス。つまりアドレスはメモリー内のどこを指すか分かるもの。変数は指定された型によって大きさが決まる。場所はアドレスで特定できる。ポインタは場所を指し示すもの。メモリー上の特定の場所を指し示すもの。メモリー上の場所はアドレスで特定するので、ポインタはアドレスを特定する情報のこと。Int *p;はポインタ変数p。ポインタ変数は、アドレスを格納する変数。ここでの型は、ポインタ変数が差す先に格納されているものの型を指定する。pが指す先に格納されているものがint型であるということ。P自体はint型ではなく、アドレスを格納するための特殊な型(ポインタ型)であることに注意する。
つまり…。Wint *pではpが指す先に格納されている型がint型であることが分かるということは、大きさが決まるということ。ポインタはメモリー上の場所(アドレス)を特定するので、ポインタ変数を実行した時点でメモリー上のアドレスは特定される。
P=&a;の&はアドレス演算子。右側に書かれたもののアドレスを求める働き。ここでは変数aのアドレスを、ポインタ変数pに格納している。つまりこの時点で、ポインタ変数pには、変数aの位置を示す情報が格納されていることになる。ポインタ変数は自動的に初期化されないので、処理で使う前にp=&a; のように値(ポインタ)を入れる。
*p=4; ポインタ変数に格納されているアドレスにあるものを実際に使うには、間接参照演算子*を使う。Pにaのアドレスが入っているので、*pはaを間接的に参照することになる。したがって*pに値を代入することは、aに代入する事と同じ意味になる。
ポインタとは?
メモリーは記憶媒体で、変数や配列を宣言するとこのメモリーに記憶される。このメモリーにはメモリー内の場所を特定するためのアドレスがあり、アドレスを見ればメモリー内のどこにその情報が記憶されているか分かる。ポインタはメモリー上の特定の場所を指し示すもの。つまり、アドレスを特定する情報のこと。ポインタ→アドレス→メモリー。ポインタを使うことで、メモリー上のアドレスを特定し、アドレスかアドレス先の値を操作することができる。配列や構造体の入っているアドレスをポインタで特定すれば、一気にこのデータの全ての要素の値を取得したり変更できる。大きな構造体の取得や変更に便利。
ポインタ特有の表現
- ポインタ変数の宣言
int *pでは、ポインタ変数pが指す先に格納されているのがint型であることを示す。つまりポインタ変数pではint型が格納されているメモリー内のアドレスを示している。 - アドレス演算子&
p = &aでは変数aのアドレスをポインタ変数pに格納している。つまり、ポインタ変数pには、変数aの位置を示す情報が格納されていることになる。これを参照渡しという。 - 間接参照演算子*
*p=4でポインタ変数pが指し示すアドレスにあるものに値を代入することができる。②でポインタ変数pには変数aのメモリー内アドレスを格納しているので、aに4が代入される。 - ポインタのポインタ
ポインタはメモリー上のアドレスを特定する変数。ポインタ自身も変数なので、ポインタという変数のアドレスもメモリのどこかに存在し、アドレス番号が付けられている。なので、ポインタにポインタのアドレスを格納することも可能。これがポインタのポインタ。


コメント